
文本到图像选项卡
首次启动 GUI 时,您将看到 txt2img 选项卡。此选项卡执行 Stable Diffusion 的最基本功能:将文本提示转换为图像。
基本用法
如果这是您第一次使用 AUTOMATIC1111,您可能希望更改这些设置。
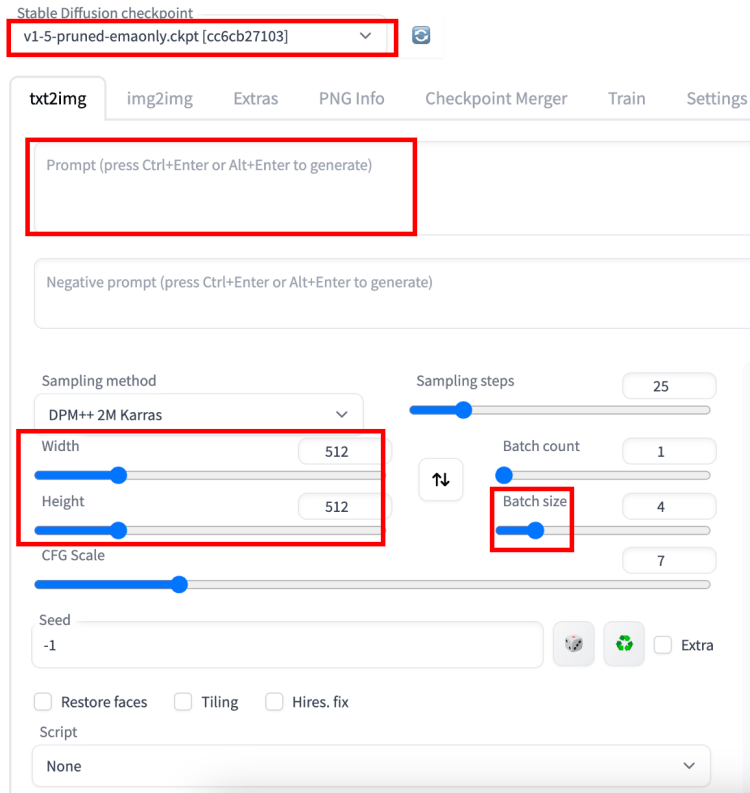
稳定扩散检查点:选择您想要的模型。初次使用的用户可以使用 v1.5 基础模型。
提示:描述您想在图像中看到的内容。下面是一个例子。有关教程,请参阅提示构建的完整指南。
萨尔瓦多·达利 (Salvador Dali) 的超现实主义猫画
宽度和高度:输出图像的大小。使用 v1 模型时,您应该至少将一侧设置为 512 像素。例如,对于纵横比为 2:3 的肖像图像,将宽度设置为 512,将高度设置为 768。
Batch size:每次生成的图像数量。您希望在测试提示时至少生成一些,因为每个都会有所不同。
最后,点击生成按钮。稍等片刻后,您将获得图像!
默认情况下,您将获得合成缩略图的附加图像。
您可以将图像保存到本地存储。首先,使用主图像画布下方的缩略图选择图像。右键单击图像以调出上下文菜单。您应该可以选择保存图像或将图像复制到剪贴板。
这就是您需要了解的所有基础知识!本节的其余部分将更详细地解释每个功能。
图像生成参数
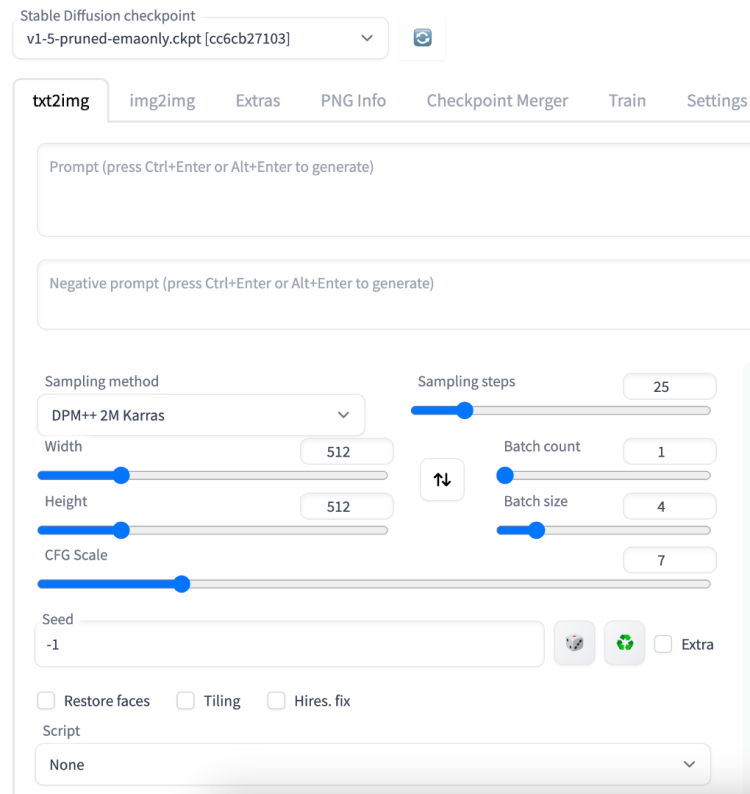
Txt2img 选项卡。
Stable Diffusion 检查点是一个用于选择模型的下拉菜单。您需要将模型文件放在文件夹stable-diffusion-webui> models>中Stable-diffusion。请参阅有关安装模型的更多信息。
下拉菜单旁边的刷新按钮用于刷新模型列表。当您刚刚将新模型放入模型文件夹并希望更新列表时使用它。
提示文本框:把你想在图像中看到的内容。要详细和具体。使用一些经过验证的关键字。您可以在此处找到简短列表或在提示生成器中找到更广泛的列表。
否定提示文本框:把你不想看到的东西放上去。使用 v2 模型时应使用否定提示。您可以使用通用否定提示。有关详细信息,请参阅本文。
采样方法:去噪过程的算法。我使用DPM++ 2M Karras,因为它很好地平衡了速度和质量。有关详细信息,请参阅本节。您可能希望避免使用任何祖先采样器(带有 a 的采样器),因为即使在较大的采样步骤中,它们的图像也不稳定。这使得调整图像变得困难。
采样步数:去噪过程的采样步数。越多越好,但也需要更长的时间。25 个步骤适用于大多数情况。
宽度和高度:输出图像的大小。对于 v1 模型,您应该至少将一侧设置为 512 像素。例如,对于纵横比为 2:3 的肖像图像,将宽度设置为 512,将高度设置为 768。使用 v2-768px 模型时,至少将一侧设置为 768。
批次计数:运行图像生成管道的次数。
批量大小:每次运行管道时要生成的图像数。
生成的图像总数等于批计数乘以批大小。您通常会更改批量大小,因为它更快。如果遇到内存问题,您只会更改批次计数。
CFG scale:Classifier Free Guidance scale 是一个参数,用于控制模型应在多大程度上尊重您的提示。
1 – 大多忽略你的提示。3 – 更有创意。7 – 遵循提示和自由之间的良好平衡。15 – 更加遵守提示。30 – 严格遵循提示。
下图显示了使用固定种子值更改 CFG 的效果。您不想将 CFG 值设置得太高或太低。如果 CFG 值太低,Stable Diffusion 将忽略您的提示。当它太高时,图像的颜色会饱和。

种子
种子:用于在潜在空间中生成初始随机张量的种子值。实际上,它控制图像的内容。生成的每个图像都有自己的种子值。如果设置为 -1,AUTOMATIC1111 将使用随机种子值。
修复种子的一个常见原因是修复图像的内容并调整提示。假设我使用以下提示生成了图像。
女人,裙子,城市夜景背景的照片

我喜欢这张图片并想调整提示以将手镯添加到她的手腕上。您将种子设置为此图像的值。种子值位于图像画布下方的日志消息中。
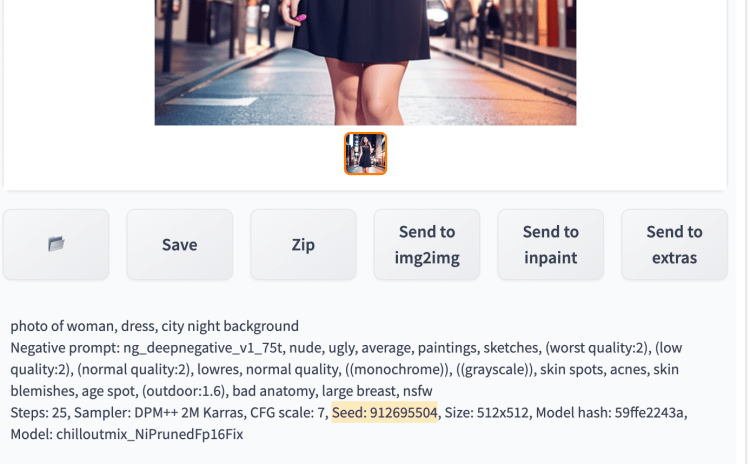
图像的种子值(突出显示)在日志消息中。
将该值复制到种子值输入框。或者使用回收按钮复制种子值。

现在在提示中添加术语“手镯”
女人,裙子,城市夜景背景,手镯的照片
你会得到一张类似的照片,她的手腕上戴着手镯。

场景可能会完全改变,因为某些关键词的强度足以改变构图。您可以在稍后的抽样步骤中尝试交换关键字。
使用骰子图标将种子设置回 -1(随机)。

额外的种子选项
检查额外选项将显示额外种子菜单。
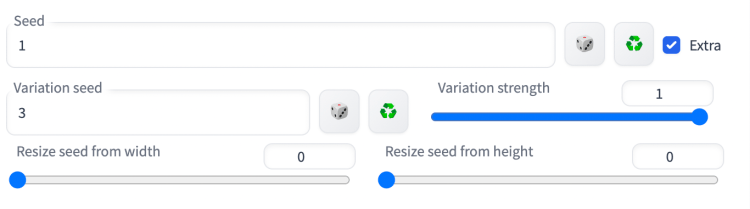
变体种子:您要使用的额外种子值。
变异强度:种子与变异种子之间的插值程度。将其设置为 0 使用种子值。将其设置为 1 使用变化种子值。
这是一个例子。假设您从相同的提示和设置生成了 2 个图像。它们有自己的种子值,1 和 3。

第一张图片:种子值为 1。

第二张图片:种子值为 3。
您想要生成这两个图像的混合。您可以将种子设置为 1,将变化种子设置为 3,并在 0 和 1 之间调整变化强度。在下面的实验中,变化强度允许您在两个种子之间产生图像内容的过渡。当变化强度从 0 增加到 1 时,女孩的姿势和背景逐渐变化。

从宽度/高度调整种子大小:即使您使用相同的种子,如果更改图像大小,图像也会发生显着变化。此设置尝试在调整图像大小时修复图像的内容。您将在宽度和高度滑块中放置新尺寸,并在此处放置原始图像的宽度和高度。将原始种子值放入种子输入框。将变异强度设置为 0 以忽略变异种子。
假设您喜欢这张 512×800 的图像,种子值为 3。
512×800
当您更改图像大小时,即使保持相同的种子值,构图也会发生巨大变化。

512×600

512×744
设置不同的尺寸会显着改变图像。
当您从高度和宽度设置中打开调整大小种子时,您将获得更接近原始尺寸的新尺寸。它们并不完全相同,但它们很接近。

512×600

512×744
使用调整大小种子选项,图像更接近原始图像。
还原人脸
Restore faces 应用了一个额外的模型,该模型经过训练可以恢复面部缺陷。以下是之前和之后的例子。

原来的

面部修复
在使用 Restore Faces 之前,您必须指定要使用的面部修复模型。首先,访问“设置”选项卡。导航到面部修复部分。选择面部修复模型。CodeFormer 是一个不错的选择。将 CodeFormer 权重设置为 0 以获得最大效果。请记住单击“应用设置”按钮以保存设置!
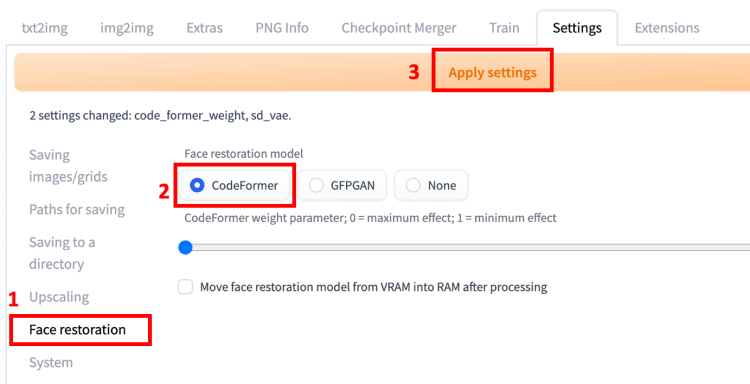
返回到 txt2img 选项卡。检查恢复面孔。面部恢复模型将应用于您生成的每张图像。
如果您发现该应用程序影响面部样式,您可能需要关闭面部修复。或者,您可以增加 CodeFormer 权重参数以降低影响。
平铺
使用平铺选项生成可以平铺的周期性图像。下面是一个例子。
花朵图案

此图像可以像墙纸一样平铺。

2×2 平铺。
使用 Stable Diffusion 的真正宝藏是允许您创建任何图像的图块,而不仅仅是传统图案。您所需要的只是提出一个文本提示。

雇用。使固定。
高分辨率修复选项应用升频器来放大图像。您需要这个,因为 Stable Diffusion 的原始分辨率是 512 像素(或某些 v2 模型的 768 像素)。图像对于许多用途来说太小了。
为什么不能将宽度和高度设置得更高,比如 1024 像素?偏离原始分辨率会影响构图并产生问题,例如生成带有两个头像的图像。
所以必须先生成两边512像素的小图。然后将其放大到更大的。
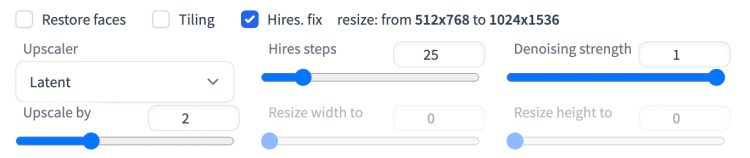
检查雇用。fix 以启用高分辨率修复。
升频器:选择要使用的升频器。请参阅这篇文章了解入门知识。
各种Latent upscaler 选项在潜在空间中缩放图像。它是在文本到图像生成的采样步骤之后完成的。该过程类似于图像到图像。
其他选项是传统和 AI 升频器的混合。有关详细信息,请参阅 AI 升频器文章。
雇用步骤:仅适用于潜在的升级者。它是放大潜像后的采样步数。
去噪强度:仅适用于潜在的升级器。该参数与image-to-image中的含义相同。它控制在执行 Hires 采样步骤之前添加到潜像的噪声。
现在让我们看看将下面的图像放大到 2 倍的效果,使用latent作为放大器。

原图

0.4

0.65

0.9
latent upscaler 的去噪强度必须高于 0.5。否则,您会得到模糊的图像。
由于某种原因,它必须大于 0.5 才能获得清晰的图像。将它设置得太高会使图像发生很大变化。
使用潜在的放大器的好处是没有像 ESRGAN 这样的其他放大器可能引入的放大伪像。Stable Diffusion 的解码器生成图像,确保风格一致。缺点是它会在一定程度上改变图像,这取决于去噪强度的值。
放大系数控制图像的放大倍数。例如,将其设置为 2 会将 512 x 768 像素的图像缩放为 1024 x 1536 像素。
或者,您可以指定“resize width to”和“resize height to”的值来设置新的图像大小。
您可以通过使用像 ESRGAN 这样的 AI upscalers 来避免设置正确的去噪强度的麻烦。一般而言,将 txt2img 和放大分为两个步骤可为您提供更大的灵活性。我不使用高分辨率修复选项,而是使用额外页面进行放大。
Generate 按钮下的按钮

从左到右:
- 读取最后一个参数:它将填充所有字段,以便您在按下“生成”按钮时生成相同的图像。请注意,将设置种子和模型覆盖。如果这不是您想要的,请将种子设置为 -1 并删除覆盖。
种子值和模型覆盖突出显示。
2.垃圾桶图标:删除当前提示和否定提示。
3. 模型图标:显示额外的网络。此按钮用于将超网络、嵌入和 LoRA 短语插入到提示中。
您可以使用以下两个按钮加载和保存提示和否定提示。该集合称为样式。它可以是一个简短的短语,例如艺术家的名字,也可以是一个完整的提示。
4.加载样式:您可以从下面的样式下拉菜单中选择多种样式。使用此按钮将它们插入到提示和否定提示中。
5.保存样式:保存提示和否定提示。您需要为样式命名。
图像文件操作
您会发现一排按钮,用于对生成的图像执行各种功能。从左到右…
打开文件夹:打开图像输出文件夹。它可能不适用于所有系统。
保存:保存图像。单击后,它会在按钮下方显示一个下载链接。如果您选择图像网格,它将保存所有图像。
压缩:压缩图像以供下载。
发送到 img2img:将所选图像发送到 img2img 选项卡。
Send to inpainting:将选中的图片发送到img2img标签中的inpainting标签。
发送到 extras:将所选图像发送到 Extras 选项卡。
img2img 选项卡
img2img 选项卡是您使用图像到图像功能的地方。大多数用户会访问此选项卡以修复图像并将图像转换为另一个图像。
图像到图像
img2img 选项卡中的一个日常用例是做……图像到图像。您可以创建遵循基本图像组成的新图像。
第一步:将基础图片拖放到img2img页面的img2img标签中。
基本图像。
第 2 步:调整宽度或高度,使新图像具有相同的纵横比。您应该会在图像画布中看到一个指示纵横比的矩形框。在上面的横向图像中,我将宽度设置为 760,同时将高度保持在 512。
第三步:设置采样方式和采样步长。我通常使用 25 个步骤的 DPM++ 2M Karass。
第 4 步:将批量大小设置为 4。
第 5 步:为新图像编写提示。我将使用以下提示。
龙的真实感插图
第 6 步:按生成按钮生成图像。调整去噪强度并重复。下面是具有不同去噪强度的图像。

0.4

0.6

0.8
img2img 生成的具有各种去噪强度的图像。
许多设置与 txt2img 共享。我只会解释新的。
调整大小模式:如果新图像的纵横比与输入图像的纵横比不同,有几种方法可以调和差异。
- “Just resize”缩放输入图像以适应新的图像尺寸。它会拉伸或挤压图像。
- “裁剪和调整大小”使新图像画布适合输入图像。不适合的部分被移除。原始图像的纵横比将被保留。
- “调整大小并填充”将输入图像适合新图像画布。额外的部分用输入图像的平均颜色填充。纵横比将被保留。
- “Just resize (latent upscale)”类似于“Just resize”,但缩放是在潜在空间中完成的。使用大于 0.5 的去噪强度以避免图像模糊。

只需调整大小

裁剪和调整大小

调整大小并填充

只需调整大小(潜在高档)
调整模式
去噪强度:控制图像变化的程度。如果设置为 0,则没有任何变化。如果设置为 1,则新图像不会跟随输入图像。0.75 是一个很好的起点,它有很多变化。
您可以使用内置脚本 poor man’s outpainting:用于扩展图像。请参阅涂装指南。
草图
您可以勾画初始图片,而不是上传图片。启动 webui 时,您应该使用以下参数启用彩色草图工具。(它已经在快速入门指南中的 Google Colab notebook 中启用)
--gradio-img2img-tool color-sketch第 1 步:导航到 img2img 页面上的草图选项卡。
第 2 步:将背景图像上传到画布。您可以使用下面的黑色或白色背景。
第 3 步:绘制您的创作草图。启用彩色素描工具后,您应该能够进行彩色素描。
第四步:写一个提示。
获奖的房子
第 5 步:按生成。
为图像到图像绘制您自己的图片。
你不必从头开始画东西。您可以使用草图功能修改图像。下面是一个示例,通过将辫子涂在上面并进行一轮图像到图像来移除辫子。使用滴管工具从周围区域中选择一种颜色。
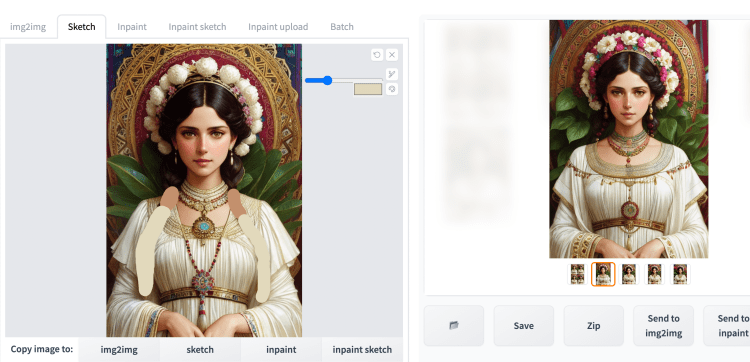
修复
也许 img2img 选项卡中最常用的功能是修复。您在 txt2img 选项卡中生成了您喜欢的图像。但是有一个小缺陷,你想重新生成它。
假设您在 txt2img 选项卡中生成了以下图像。你想重新生成人脸,因为它是乱码。您可以使用发送到修复按钮将图像从 txt2img 选项卡发送到 img2img 选项卡。

当切换到 img2img 页面的 Inpaint 选项卡时,您应该会看到您的图像。使用画笔工具在要重新生成的区域上创建一个蒙版。
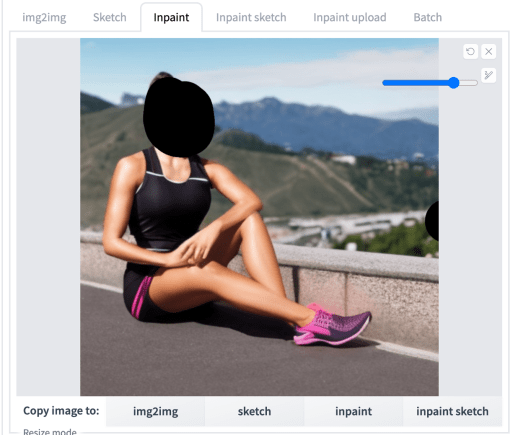
由于您使用了“发送到修复”功能,因此图像大小等参数已正确设置。你通常会调整
- 去噪强度:从 0.75 开始。减少改变更多。增加改变较少。
- 面膜内容:原装
- 蒙版模式:修复蒙版
- 批量大小:4
按生成按钮。选择一个你喜欢的。

修补素描
Inpaint sketch 结合了修复和素描。它可以让您像在草图选项卡中一样进行绘画,但只会重新生成绘画区域。未上漆的区域没有变化。下面是一个例子。
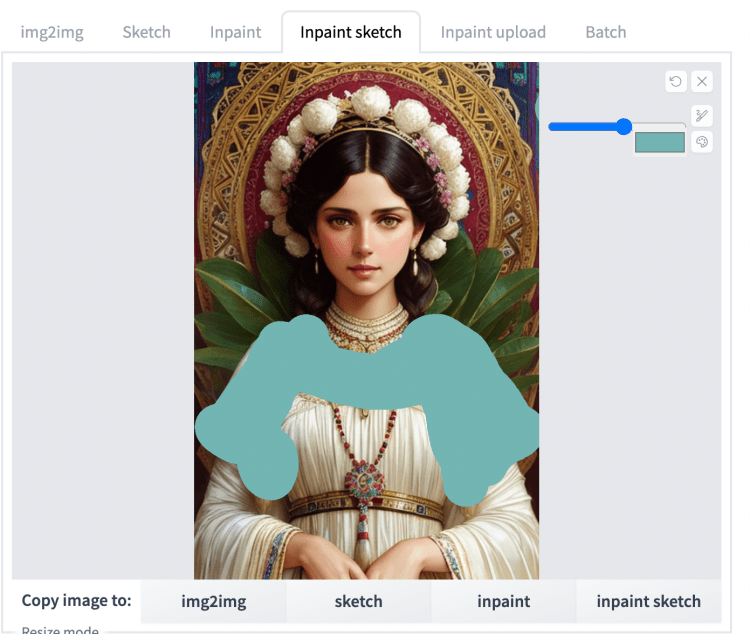
修补素描。



来自修补草图的结果。
修复上传
Inpaint upload 允许您上传单独的遮罩文件而不是绘制它。
批
Batch 让您可以为多个图像修复或执行图像到图像。
从图像中获取提示
AUTOMATIC1111 的 Interogate CLIP 按钮将您上传的图像带到 img2img 选项卡并猜测提示。当您想处理您不知道提示的图像时,它很有用。要从图像中获得猜测的提示:
第 1 步:导航到 img2img 页面。
第 2 步:将图像上传到 img2img 选项卡。
第 3 步:单击询问 CLIP 按钮。
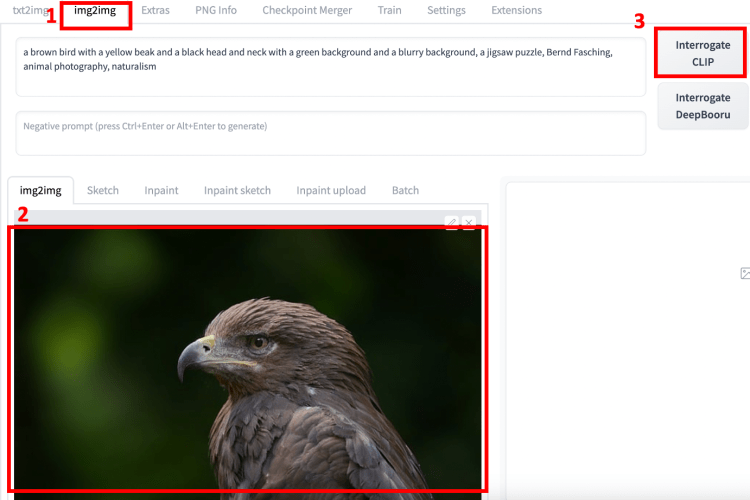
提示文本框中将出现提示。
Interrogate DeepBooru 按钮提供了类似的功能,除了它是为动画图像设计的。
升级
您将转到用于放大图像的额外页面。为什么需要 AUTOMATIC1111 来放大图像?您可以使用 PC 上通常不可用的 AI 升频器。无需支付 AI 升级服务费用,您可以在此处免费进行。
基本用法
按照以下步骤升级图像。
第 1 步:导航到“额外”页面。
第 2 步:将图像上传到图像画布。
第三步:在resize标签下设置Scale by factor。新图像的每一侧都会大很多倍。例如,一张 200×400 的图像将变为 800×1600,比例因子为 4。
第 4 步:选择 Upscaler 1. 流行的通用 AI upscaler 是 R-ESRGAN 4x+。
第 5 步:按生成。你应该在右边得到一个新图像。
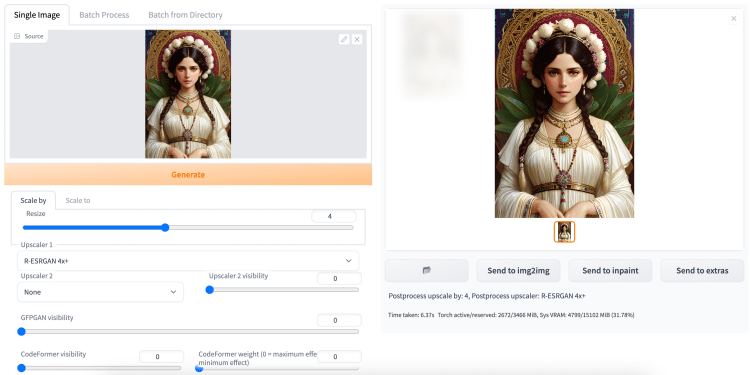
确保以全分辨率检查新图像。例如,您可以在新选项卡中打开新图像并禁用自动调整。如果缩小,放大器可能会产生您可能会忽略的伪像。
例如,即使您不需要放大 4 倍,它仍然可以将其放大到 4 倍并稍后调整大小。这可能有助于提高清晰度。
缩放至:您可以在“缩放至”选项卡中指定要调整大小的尺寸,而不是设置比例因子。
升级器
AUTOMATIC1111 默认提供一些升频器。
升频器:升频器下拉菜单列出了几个内置选项。您也可以安装自己的。有关说明,请参阅 AI 升频器文章。
Lanczos 和 Nearest 是老派的高端品牌。它们没有那么强大,但行为是可以预测的。
ESRGAN、R-ESRGAN、ScuNet 和 SwinIR 是 AI 升级器。他们可以从字面上编造内容以提高分辨率。有些人接受过粒子风格的训练。找出它们是否适用于您的图像的最佳方法是测试它们。我现在听起来像是一张破唱片,但一定要以全分辨率仔细查看图像。
Upscaler 2:有时,您想结合两个 upscaler 的效果。此选项可让您合并两个升频器的结果。混合量由 Upscaler 2 Visibility 滑块控制。较高的值显示更多的 upscaler 2。
找不到您喜欢的升级器?您可以从模型库中安装额外的升频器。请参阅安装说明。
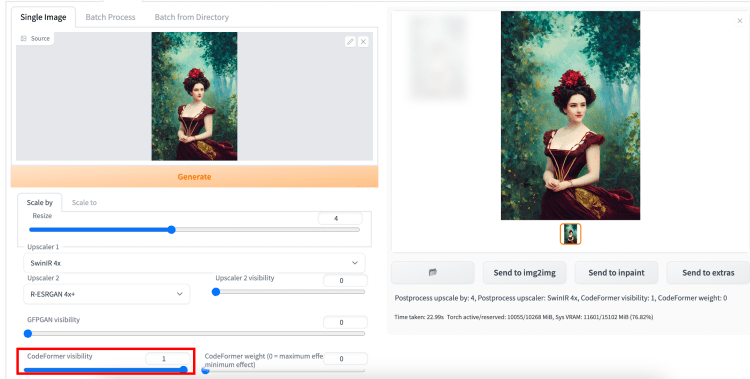
面部修复
您可以选择在放大过程中恢复面孔。有两个选项可用:(1) GFPGAN 和 (2) CodeFormer。设置其中任何一个的可见性以应用更正。作为缩略图的规则,您应该设置可以避免的最低值,这样图像的风格就不会受到影响。
巴布亚新几内亚信息
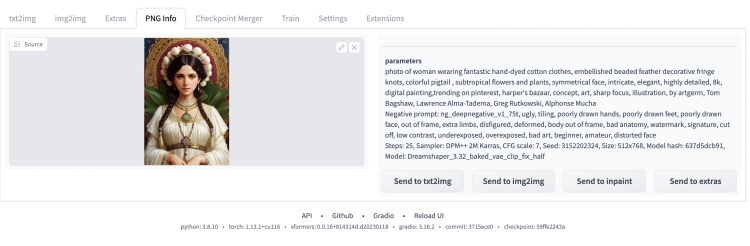
许多 Stable Diffusion GUI,包括 AUTOMATIC1111,将生成参数写入图像 png 文件。这是一个方便的快速取回生成参数的函数。
如果图像是由 AUTOMATIC1111 生成的,您可以使用发送到按钮将参数快速复制到各个页面。
当您在网络上找到图像并想查看提示是否留在文件中时,它很有用。
即使对于未生成的图像,此功能也可能有帮助。您可以快速将图像及其尺寸发送到页面。
检查点合并
AUTOMATIC1111 的检查点合并用于合并两个或多个模型。您最多可以组合 3 个模型来创建一个新模型。它通常用于混合两个或多个模型的样式。但是,不能保证合并结果。它有时会产生不需要的伪影。
主要模型(A、B、C):输入模型。合并将根据显示的公式完成。公式将根据所选的插值方法而变化。
插值方法:
- 无插值:仅使用模型 A。这用于文件转换或替换 VAE。
- 加权和:合并两个模型A和B,对B施加乘数权重M。公式为A * (1 – M) + B * M。
- 添加差异:使用公式 A + (B – C) * M 合并三个模型。
检查点格式
- ckpt:原始检查点模型格式。
- safetensors:SafeTensors 是 Hugging Face 开发的一种新的模型格式。它是安全的,因为与 ckpt 模型不同,加载 Safe Tensor 模型不会执行任何恶意代码,即使它们在模型中也是如此。
Bake in VAE:将 VAE 解码器替换为所选的解码器。它是为了用 Stability 发布的更好的版本替换原来的版本。
火车
训练页面用于训练模型。它目前支持文本反转(嵌入)和超网络。我在使用 AUTOMATIC1111 进行训练时运气不好,所以我不会介绍这一部分。
设置
AUTOMATIC1111 的设置页面上有大量设置列表。我无法在本文中逐一介绍它们。这里有一些你想检查的。
确保在更改任何设置后单击应用设置。
面部修复
确保选择默认的面部恢复方法。CodeFormer 是一个很好的工具。
稳定扩散
下载并选择 Stability 发布的 VAE,以改善 v1 模型中的眼睛和面部。