
网页服务
这是最简单的选择。去访问下面的网站并输入您的提示。
目前只有有限的 Web 选项可用。但在接下来的几周内应该会有更多。
以下是您可以运行 Stable Diffusion 2.0 的网站列表
- 拥抱的脸
- 基站
设置仅限于无。
本地安装
安装基础软件
我们将介绍如何在 AUTOMATIC1111 GUI 中使用 Stable Diffusion 2.0。按照您各自环境的安装说明进行操作。
这个 GUI 可以很容易地安装在 Windows 系统中。您将需要具有至少 6GB VRAM 的专用 GPU 卡才能使用此选项。
下载稳定扩散 2.0 文件
安装后,您需要下载两个文件才能使用 Stable Diffusion 2.0。
- 下载模型文件 (768-v-ema.ckpt)
- 下载配置文件,重命名为
768-v-ema.yaml
将它们都放在模型目录中:
stable-diffusion-webui/models/Stable-diffusion谷歌公司
Stable Diffusion 2.0 也可在快速入门指南中的 Colab notebook 以及其他一些流行模型中找到。
如果您没有专用 GPU 卡,这是一个不错的选择。您不需要付费帐户,但它有助于防止断开连接并在繁忙时间获取 GPU 实例。
转到 Google Colab 并开始一个新笔记本。
在运行时菜单中,选择更改运行时类型。在硬件加速器字段中,选择 GPU。
首先,您需要下载 AUTOMATIC1111 存储库。
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui然后升级到python 3.10。
!sudo apt-get update -y!sudo apt-get install python3.10!sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.7 !sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.10 2!sudo apt-get install python3.10-distutils!wget https://bootstrap.pypa.io/get-pip.py && python get-pip.py下载 Stable Diffusion 2.0 模型和配置文件。
!wget https://huggingface.co/stabilityai/stable-diffusion-2/resolve/main/768-v-ema.ckpt -O /content/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.ckpt!wget https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml -O /content/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.yaml最后,运行 GUI。您应该更改下面的用户名和密码。
%cd stable-diffusion-webui!python launch.py --share --gradio-auth username:password这一步需要一段时间,所以请耐心等待。完成后,您应该会看到一条消息:
在公共 URL 上运行:https://xxxxx.gradio.app
按照链接启动 GUI。
使用稳定扩散 2.0
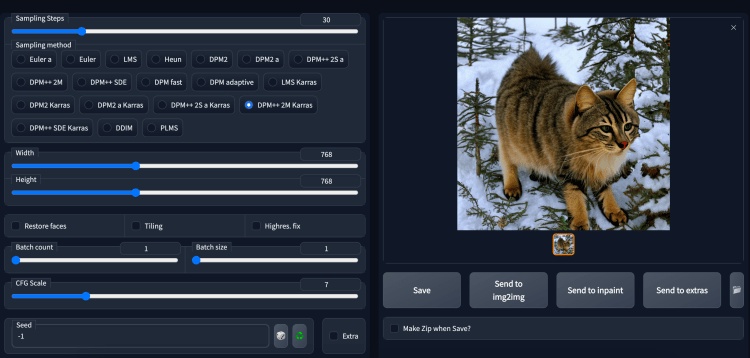
选择稳定扩散 2.0 检查点文件 768-v-ema.ckpt。

由于模型是在 768×768 图像上训练的,因此请确保将宽度和高度设置为 768。30 步 DPM++2M Karras 采样器适用于大多数图像。
比较 v1 和 v2 模型
许多人做的第一件事是比较 v1 和 v2.0 之间的图像。
进行比较时需要注意一些事项。
使用 v1.4 或 v1.5 时,确保将图像大小设置为 512×512。它对那个尺寸的图像进行了微调,768×768 效果不佳。
使用 v2.0 时将图像大小设置为 768×768。
(注意:根据公告,v2 旨在生成 512×512 和 768×768 图像。虽然早期测试似乎表明 512×512 不太好,但可能只是我们需要解决的一些软件设置问题.)
不要重复使用 v1 提示
适用于 v1 模型的提示可能不适用于 v2。这是意料之中的,因为 v2 已切换到更大的 OpenClip H/14 文本编码器(比 v1 模型大近 6 倍)并且是从头开始训练的。
对比一:未来感卧室
这是具有相同提示的 v2.0 代。相距不远,但我更喜欢 v1.4。




稳定扩散 2.0 图像。
这并不是说 v2.0 不好,而是提示针对 v1.4 进行了优化。
对比二:墨滴写真
这个提示对 v2.0 不太适用……




稳定扩散 2.0 图像
它产生了更逼真的风格,这不是我想要的。
我不认为 v2.0 更糟糕。提示只是需要重新优化。
如果你必须重用 v1 提示符……
您可以尝试提示转换器,它首先使用 v1 生成图像并使用 CLIP 询问器 2 询问提示。实际上,它给出了语言模型将描述的提示。
滴墨提示失败的提示是
[amber heard:Ana de Armas:0.7], (touching face:1.2), shoulder, by agnes cecile, half-body portrait, extremely luminous bright design, pastel colors, (ink drips:1.3), future lights
这被翻译成
脸上有水彩画的女人的画,Ignacy Witkiewicz 的水彩画,tumblr,过程艺术,强烈的水彩画,富有表现力的美丽画作,用明亮的水彩画
这些图像与 v1 不太一样,但看起来确实更好。




v2.0 图像生成使用提示转换为 v2。
v1 技术可用
我的第一印象是为 v1 开发的许多技术仍然有效。例如,关键字混合效果很好。不过,使用名人名字的效果似乎有所减弱。

使用关键字混合生成的 Stable Diffusion 2.0 图像。
提示建设
我的一项观察是 Stable Diffusion 2.0 在更长、更具体的提示下效果更好。请注意,这对于 v1 也是如此,但对于 v2 似乎更是如此。
为了说明这一点,下面是使用单词提示“猫”生成的图像。
我们使用 v1.5 得到了预期的结果:

v1.5 图像提示“猫”。
下面是我使用 v2.0 得到的相同提示。

v2.0 图像提示“猫”。
它们仍然与 cat 有点相关,但并不完全是用户所期望的。
如果我们使用更长、更具体的提示怎么办?
一张俄罗斯阿甘猫戴着墨镜在沙滩上放松的照片

v1.5 图片

v2.0 图片
这就是 Stable Diffusion 2.0 的亮点:它可以生成质量更高的图像,因为它们与提示的匹配度更高。
这可能是更大的语言模型的好处,它增加了网络的表达能力。2.0 能够比 v1 模型更好地理解文本提示,并允许您设计更精确的提示。
概括
现在仍是 Stable Diffusion 2.0 的早期阶段。我们刚刚让软件运行起来,我们正在积极探索。当我发现如何更有效地使用 2.0 时,我会写更多。敬请关注!