
软件
我们将使用 AUTOMATIC1111Stable Diffusion GUI 生成逼真的人物。您可以在 Windows、Mac 或 Google Colab 上使用此 GUI。
迅速的
在本节中,您将学习如何逐步构建逼真的照片风格的高质量提示。
让我们从一个坐在餐馆外面的女人的简单提示开始。让我们使用 v1.5 基础模型。
迅速的:
年轻女子的照片,突出头发,坐在餐厅外面,穿着裙子
型号:稳定扩散v1.5
采样方式:DPM++ 2M Karras
采样步数:20
CFG 比例:7
尺寸:512×768



好吧,这并没有那么顺利……
否定提示
让我们添加一个否定提示。这个否定提示非常简单。它旨在产生更好的解剖结构并避开非现实风格。
否定提示:
disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w



它正在做某事:女性看起来更好。上半身看起来很不错。
但下半身的解剖结构仍然存在问题。还有很大的改进空间。
灯光关键词
摄影师的很大一部分工作是设置良好的照明。一张好照片有有趣的灯光。这同样适用于稳定扩散。让我们添加一些照明关键字和一个控制视角的关键字。
- 边缘照明
- 工作室照明
- 看着相机
迅速的:
photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera
否定提示:
disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w



这些照片立即看起来更有趣。您可能会注意到解剖结构不太正确。不用担心。有很多方法可以修复它。我会在文章后面告诉你。
相机关键词
dslr、ultra quality、8K、UHD 等关键字可以提高图像质量。
迅速的:
photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD
否定提示:
disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w



我不能说它们肯定更好,但包括它们肯定不会有什么坏处……
面部细节
最后,一些关键字可以作为甜味剂来描述眼睛和皮肤。这些关键字旨在呈现更逼真的面孔。
- 非常详细的有光泽的眼睛
- 高细节皮肤
- 皮肤毛孔
使用这些关键词的副作用是让拍摄对象更靠近相机。
将它们放在一起,我们有以下最终提示。
迅速的:
photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores
否定提示
disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w



您对基础模型能够生成这些高质量的逼真图像感到惊讶吗?我们甚至还没有使用特殊的逼真模型。它只会变得更好。
控制面孔
混合两个名字
您想在多个图像中生成相同的外观吗?一个技巧是利用名人。他们的容貌是他们身体中最容易辨认的部分。所以他们保证是一致的。
但是我们通常不想用他们的脸。他们太有辨识度了。您想要一张具有特定外观的新面孔。
诀窍是使用提示调度来混合两个面孔。AUTOMATIC1111 中的语法是
[人 1:人 2:因素]
factor is a number between 0 and 1. It indicates the fraction of the total number of steps when the keyword switches from person 1 to person 2. For example, [Ana de Armas:Emma Watson:0.5] with 20 steps means the prompt uses Ana de Armas in steps 1 – 10, and uses Emma Watson in steps 11-20.
您可以简单地将其放入提示中,如下所示。
迅速的:
photo of young woman, [Ana de Armas:Emma Watson:0.5], highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores
否定提示
disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w

[安娜·德·阿玛斯:艾玛·沃特森:0.5]

[艾梅柏·希尔德:艾玛·沃特森:0.5]
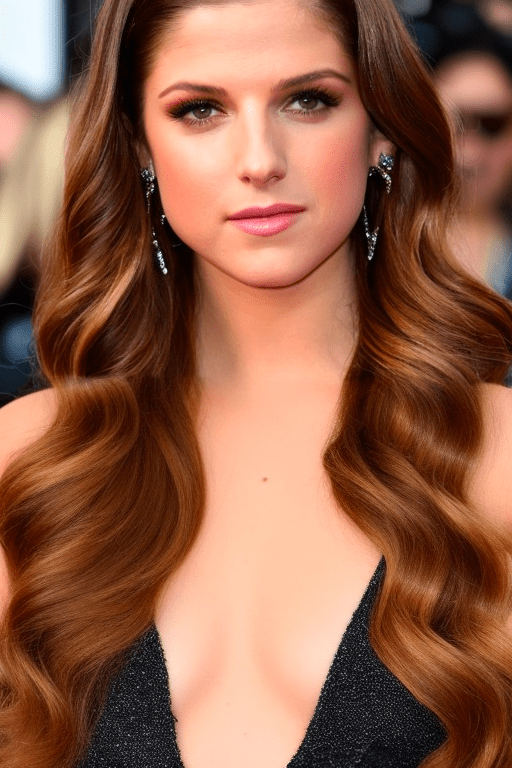
[安娜·肯德里克:丽莎君主 0.5]
通过仔细调整系数,您可以调节两张脸的比例。
混合一个名字
您是否注意到使用两个名称时背景和构图发生了巨大变化?这就是联想效应。女演员的照片通常与某些场景相关联,例如颁奖典礼。
整体构图由第一个关键字设置,因为采样器在前几个步骤中降噪最多。
利用这个想法,我们仍然可以在前几步使用woman ,然后只换一个名人的名字。这在保留构图的同时提供了将普通面孔与名人融合在一起的效果。
提示是这样的:
photo of young [woman:Ana de Armas:0.4], highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores
否定提示可以保持不变。
disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w

[女性:Ana de Armas:0.4]

[女人:艾梅柏希尔德:0.6]

[女:艾玛沃特森:0.6]
使用这种技术,我们可以在一定程度上控制面部的同时保持构图。
修复面孔
修补是一种既能保持构图又能完全控制面部的技术。
在 txt2img 选项卡中生成图像后,单击发送到修复。
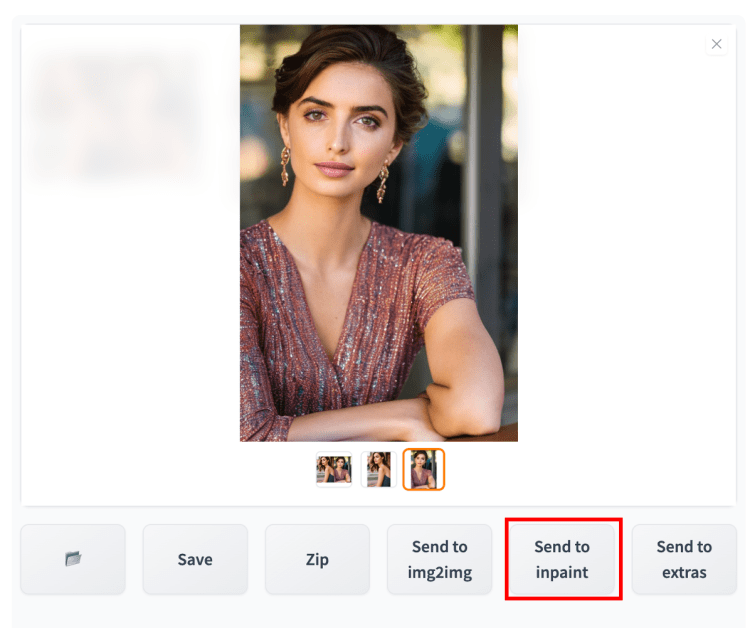
在修复画布中,绘制覆盖面部的蒙版。
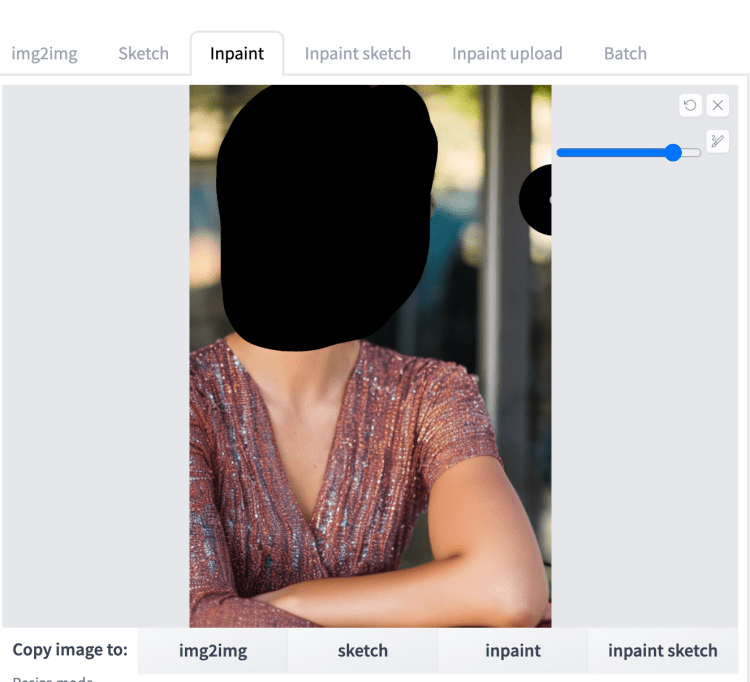
现在修改提示以包括两个面的混合。例如
photo of young [Emma Watson: Ana de Armas: 0.4], highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores
将去噪强度设置为 0.75,将批量大小设置为 8。点击“生成”并挑选出效果最好的一个。

[艾玛·沃特森:安娜·德·阿玛斯:0.4]

[艾梅柏·希尔德:艾玛·沃特森:0.5]

[安娜·肯德里克:丽莎君主 0.4]
修复缺陷
您不需要一次性生成具有正确解剖结构的逼真人物。重新生成图像的一部分相当容易。
让我们来看一个例子。下图看起来不错,只是手臂变形了。
要修复它,首先单击发送到修复以将图像和参数发送到 img2img 选项卡的修复部分。
在 img2img 选项卡的修复画布中,在有问题的区域上绘制蒙版。
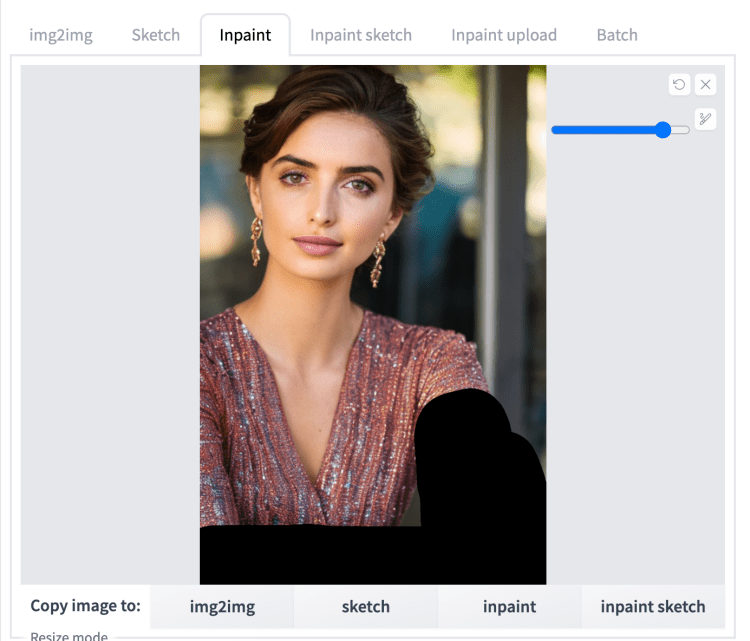
将种子设置为 -1(随机),去噪强度设置为 1,批量大小设置为 8。
您可以尝试修复区域设置——整张图片或仅蒙版。
点击生成。
你会有一些不好的。但纯粹是偶然,你应该看到一个像样的。如果没有,请再次按生成。
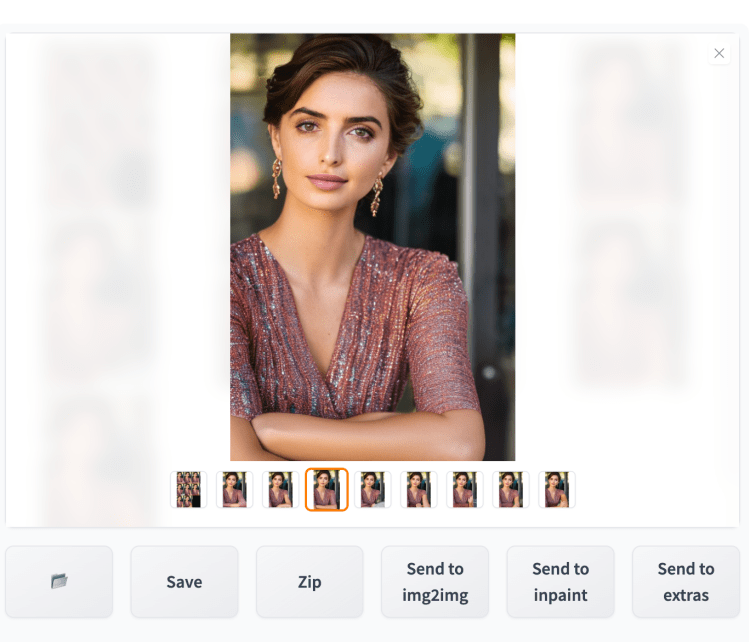
您无需一次完成完美修复。您可以使用修复迭代地优化图像。当您看到图像朝正确的方向移动时,请按“发送”进行修复。
现在你正在对新形象采取行动。逐渐降低去噪强度,以保留图像的内容。下面是进行第二轮修复的示例。去噪强度设置为0.6。

楷模
到目前为止,我们只使用了 Stable Diffusion v1.5 基础模型来生成逼真的人物。你知道有专门训练来生成逼真的图像的模型吗?
当你使用它们时,事情只会变得更好。
您将了解一些常用的。我们会研究
- F222
- 哈桑混合1.4
- 逼真的视觉 v2
- 休闲组合
- 梦幻般的真实感
- URPM
我知道我错过了一些,但请耐心等待。
我将使用相同的提示
photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores
和否定提示
disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
我将包括每个模型的直接下载链接。您只需将链接复制并粘贴到我们的 AUTOMATIC1111 Colab 笔记本中的“Model_from_URL”字段。
警告
- 几乎所有这些都倾向于生成露骨的图像。在提示中使用dress和在否定提示中使用nude 等服装术语来压制它们。
- 有些型号有自己的限制性更强的许可证。在使用它们或将它们整合到产品中之前阅读它们。
F222
直接下载链接:
https://huggingface.co/acheong08/f222/resolve/main/f222.ckpt


F222 生成穿着漂亮衣服的逼真人物。遗憾的是,该模型不再处于开发阶段。
哈桑混合1.4
模型页
直接下载链接
https://huggingface.co/hassanblend/hassanblend1.4/resolve/main/HassanBlend1.4_Safe.safetensors


Hassan Blend v1.4 在大量露骨图像上进行了微调。
现实视觉 v2.0
模型页
直接下载链接
https://civitai.com/api/download/models/29460


Realistic Vision v2 是用于生成照片风格图像的全能模型。除了写实人物,动物和场景也不错。
根据我的经验,解剖学非常好。
休闲组合
模型页
直接下载链接
https://civitai.com/api/download/models/11745Chillout Mix 是 F222 的亚洲版本。它经过训练可以生成照片风格的亚洲人。



梦幻般的真实感
模型页
直接下载链接
https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/resolve/main/dreamlike-photoreal-2.0.ckpt


Dreamlike Photoreal 是一个全能的照片风格模型。肖像图像往往有点饱和。
URPM
模型页
直接下载链接
https://civitai.com/api/download/models/15640


URPM 是一种使用显式图像进行微调的模型。解剖学通常非常好。图像与 Realistic Vision v2 类似,但更加精致。
比较
为了让大家直接对比逼真的模型,我使用了ControlNet来固定姿势。(稍后会详细介绍)
使用相同的提示、否定提示和种子。

稳定扩散 v1.5

F222

哈桑混合 1.4

逼真的视觉 v2

休闲组合

梦幻般的真实感

URPM
特写视图:

稳定扩散 v1.5

F222

哈桑混合 1.4

逼真的视觉 v2

休闲组合

梦幻般的真实感

URPM
你最喜欢哪个现实模型?在评论中让我知道!
LoRA、超网络、文本倒置
您可以通过补充模型修改器(例如 LoRA、超网络和文本反演)来进一步调入模型。
找到它们的最佳地点是 civitai。
韩国审美
将 Ulzzang-6500 与 Chillout Mix 结合使用可以打造韩国偶像造型。

较暗的图像
epi_noiseoffset 是一种 LoRA,它可以在稳定扩散中产生比正常情况下更暗的图像。使用黑暗的关键字,如“黑暗的工作室”、“夜晚”、“昏暗的灯光”等。
迅速的:
night, (dark studio:1.3) photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores <lora:epiNoiseoffset_v2:1>
否定提示:
disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
下面的图像是用 URPM 模型生成的。


名人罗拉
有大量粉丝制作的 LoRA 模型向他们喜欢的艺术家致敬。
艾丽丝·贾科蒂
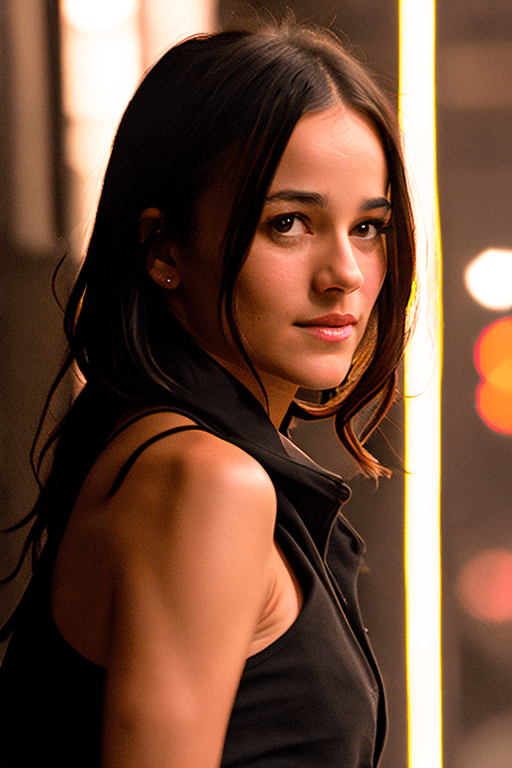
娜塔莉·波特曼「LoRa」

衣服
这件中国汉装 LoRA(应用于 Chillout Mix)非常适合生成漂亮的传统汉服。

控制姿势
控制网
ControlNet 已成为控制人体姿势和肖像构图的事实标准。
但是如何获取参考图像呢?一种简单的方法是访问 Unsplash 等免费照片网站。使用 man、woman、stand、sit 等关键字进行搜索。您会找到构图正确的图像。
使用 openpose ControlNet。有关详细信息,请参阅 ControlNet 文章。


两个人的ControlNet
如果没有 ControlNet,几乎不可能控制场景中两个或更多人的构图和姿势。现在,您只需找到一个参考图像,您就可以开始工作了。

参考图片。

休闲组合

逼真的视觉 v2
升级器
SD v1 模型的原始分辨率为 512×512 像素。为防止出现重复字符等问题,您应将至少一侧设置为 512 像素。
因此,图像可能太小而无法在以后使用。
您可以使用 AI upscalers 放大图像,而不必担心变得模糊。他们有能力在您放大图像时创建内容来填充细节。
为现实人物使用升级器的技巧
逼真照片的升级器的几点注意事项
- 大多数升级器都会改变图像。
- 尝试应用两个升频器。第一个是像 Lanczos 这样的传统产品。第二个是像 R-ESRGAN 这样的 AI upscaler。您应该应用尽可能少的 AI upscaler。
- 面部修复也一样。全力应用它会引入伪影。应用你可以逃脱的最少数量。
- 您可以扩展到比您需要的更大的规模。然后缩小它。这样,您可以承受放大后的图像有点模糊。
ControlNet 没有升级器
您可以尝试在使用 ControlNet 时生成具有最终分辨率的图像。它之所以可行,是因为 ControlNet 修复了姿势并防止了常见问题,例如生成两个重复的头部或身体。
继续尝试将图像大小设置为 1200×800。您有机会使用升级器来逃脱惩罚!
升级后的图像到图像
要消除由升级器引入的伪影,您可以使用低去噪强度(例如 0.1 到 0.3)进行图像到图像,同时保持提示相同。
这个技巧可以让模型生成与模型风格一致的细节,同时又不会过多地改变图像。
缺点是图像会略有改变,具体取决于您使用的去噪强度。
概括
下面是一些带回家的。
- 从模型部分开头的样板提示和否定提示开始。您可以通过更改自定义图像
- 种族——非裔美国人、西班牙裔、俄罗斯人、欧洲人……
- 发型 – 长发、短发、发髻、马尾辫、辫子……
- 服装——连衣裙、上衣、牛仔裤、夹克。转到您最喜欢的服装店的网站并获取一些关键字提示。
- 活动——他或她在做什么
- 环境 – 繁忙的街道、房屋内、海滩上……
- 选择型号
- F222 或 Realistic Vision v2 适合平衡、现实的人。
- Hassan Blend v1.4 或 URPM 以获得更精致的外观。
- 适合亚洲人的 Chillout Mix。
- SD 1.5 如果你想炫耀你的高超提示技巧……
- 加入 LoRA、文本倒置或超网络以输入您想要的效果。
- 以良好的构图为目标。不要害怕使用多轮修复来修复缺陷或重新生成面孔。
- 将 ControlNet 与库存照片结合使用以获得良好的姿势和构图。
- 对 AI 升级器保持温和。