

什么是稳定扩散 Deforum?
Deforum Stable Diffusion 是 Stable Diffusion 的一个版本,专注于创建视频和使用 Stable Diffusion 创建的图像的过渡。它是一个开源和社区驱动的工具。如果您想贡献和支持该项目,无论经验水平或专业领域如何,您都可以联系开发人员。
在本教程中,我将向您展示如何根据文本提示创建视频以补充音乐并创建音乐视频,例如这个或这个。一切都使用 Stable Diffusion Deforum Google Colab notebook。
所以,不要再浪费时间了!
首次设置帐户
如前所述,在本教程中,我将向您展示如何为 Stable Diffusion Deforum 视频创建创建一个完整的管道。我们将在线运行所有内容,无需您的 GPU。将来会有关于如何在本地运行 Stable Diffusion 的教程,但现在还没有。今天,学习如何在没有任何先进设备的情况下免费在线完成,您只需要对艺术、人工智能和想象力的热情。
但是,最后,您还需要什么?
对于本教程,您需要:
Google 帐户和至少 6 GB 空间在您的 google 驱动器上 Huggingface 帐户一台计算机。不需要任何花哨的互联网访问
我们走吧!
在您的 Google Drive 上复制 Deforum
转到 Deforum Stable Diffusion v0,5 并使用这个简单的按钮将其复制到你的谷歌驱动器上
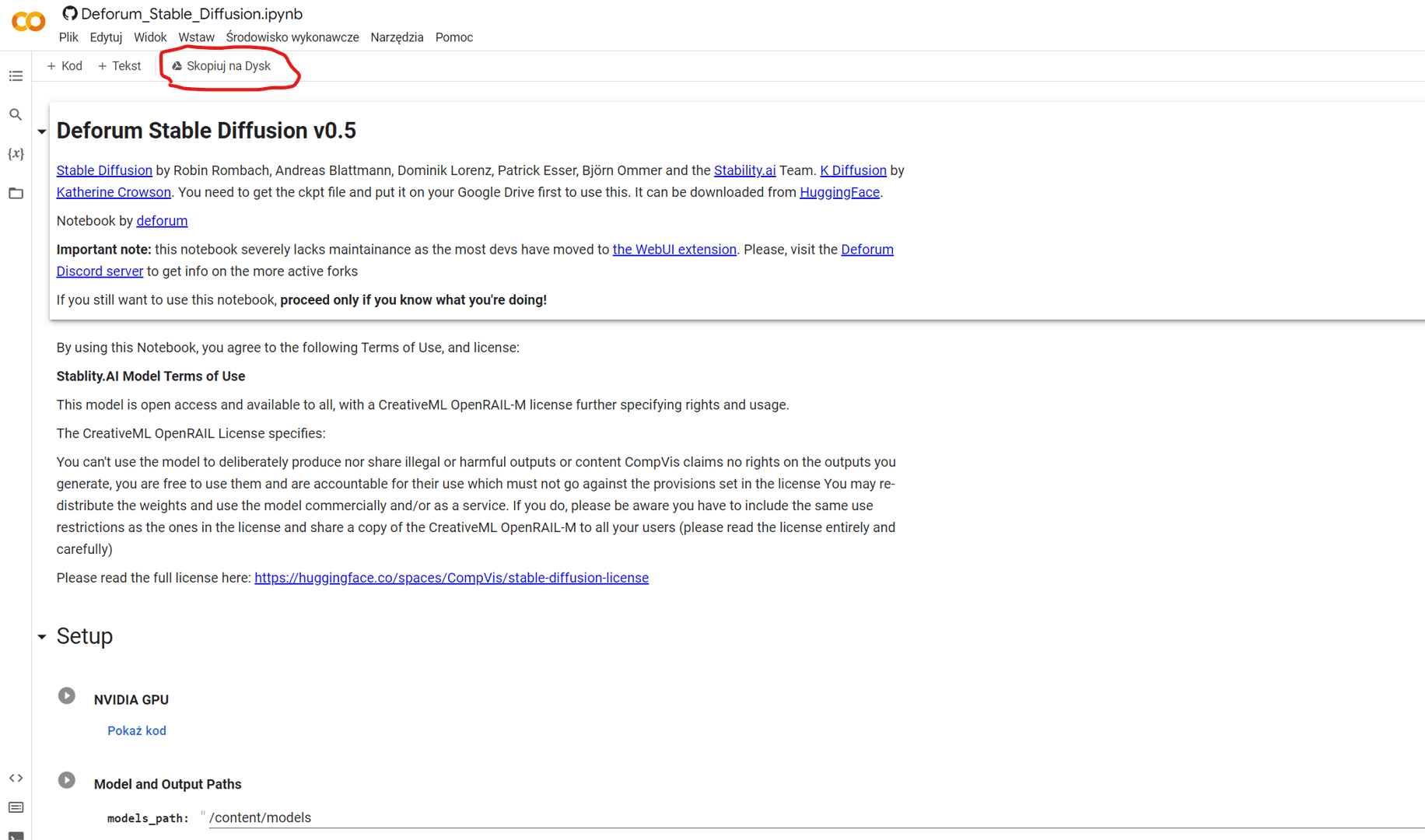
按下按钮后,我们将被重定向到将 Google Colab 笔记本复制到我们的 Google 驱动器。关闭原来的那个,你永远不会再使用它:)
第一次跑步!
现在,您可以完全访问 Google Collab,我们需要将它连接到外部 GPU。

请注意,您有一些免费的 google Colab 积分,如果用完了,您可以购买更多积分或等待一两天以刷新积分。
Google 云端硬盘想要访问您的 Google 帐户!
当您成功连接到 NVIDIA GPU(通常是 Tesla T4、15360 MiB、15101 MiB)时,您已经运行了剩余的代码,但为此,您需要授予对您的 Google Drive 的访问权限。如果你想使用它,你必须授予访问权限,但我鼓励你先阅读所有的条款和条件,如果你真的同意它们,请按“允许”按钮。
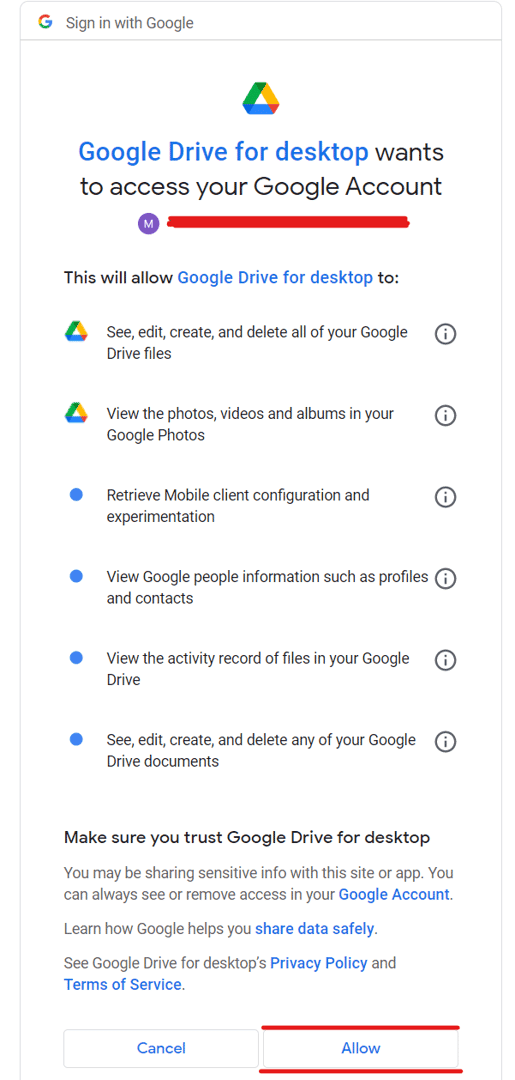
在您接受访问后,将在您的谷歌驱动器上创建两个文件夹:
ai/模型和 ai/stablediffusion。
在 ai/models 文件夹中,将存储所有可用于生成视频的稳定扩散模型,并在 ai/stablediffusion 文件夹中存储所有输出图像。

设置环境和 python 定义
当您运行这两个代码时,它们非常简单。连接需要几分钟,但仅此而已。

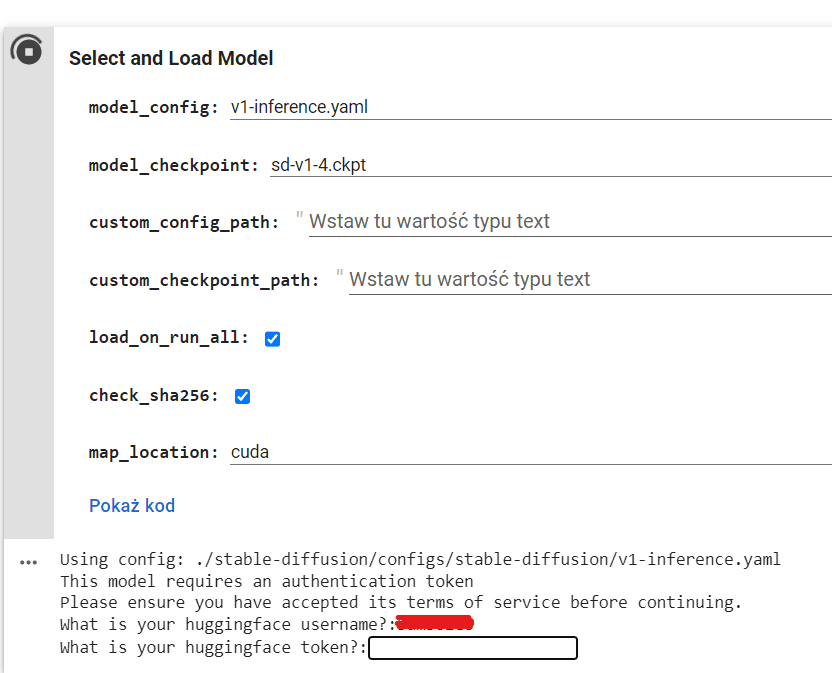
选择和加载模型
这需要我们采取一些行动。当我们运行代码时,它会向我们询问我们的 hugginface 用户名和 hugginface 令牌。如果这样做,您必须等待几分钟才能下载模型、配置等。
我们都准备好了!
好的,我们每次启动 google colab 时都必须重复之前的所有步骤(除了提供拥抱脸的用户名和令牌)。
但现在我们可以去尝试设置,让我们的 AI 生成的视频栩栩如生!
我们将仔细研究动画设置,我们在其中设置视频/相机移动的所有运动和其他重要因素。
我们还需要提供提示,以便我们可以从文本生成视频。
这里的最后一部分将使用“运行”部分运行所有内容。
动画设置
乍一看,它们可能真的让人不知所措,但事实并非如此。我们将介绍所有重要的内容并进行解释,因此您将有一个起点,然后可以随心所欲地使用它!

如果您选择2D动画,您将仅使用“运动参数设置”中的角度和缩放
如果您选择3D动画,您还将使用平移和旋转部分。
视频输入适用于您想要使用稳定扩散模型更改视频的选项。
无选项将创建单个图像。用来查看初始图像是否符合您的视觉效果很好。
您在开始时看到的视频是作为 2D 动画创建的,因此我们将通过 2D 生成使它变得简单
最大帧设置意味着将生成多少帧。我总是每秒生成 24 帧,有些人每秒生成 12 帧。
因此,对于 10 秒的视频,我将生成 240 帧。
边框部分有 2 个选项:
Wrap,它将像素从上一帧的另一侧拉到下一个图像。
Replicate,它重复上一张图像的边缘并将其应用于下一张图像。
我总是使用 wrap 选项
运动参数
正如我之前提到的,角度和缩放是 2D 动画的设置,平移、旋转和透视翻转是 3d 生成的。

你可以看到前几代的一些数字。
角度值设置:0:(0)、95:(0)、96:(0.2) 表示从第 0 帧开始视频不会旋转。它直到第 95 帧才会旋转,但对于第 96 帧,它会随着每张图片的每一帧旋转 0.2 度。
缩放值设置 0:(1.00), 95:(1.00), 96:(1.02) 意味着从第 0 帧开始,视频将不会缩放,直到第 95 帧,但对于第 96 帧,它会随每一帧缩放减少 0.02。
角度的默认值为 0,这意味着如果您输入 0.1 或 -0.1,它将顺时针或逆时针旋转。对于缩放,默认值为 1,因此当您将值设置为 0.99 时,它会慢慢缩小每一帧,而设置为 1.01 时,它会慢慢放大。
重要说明– 首先从较小的值开始,看看视频如何随它们变化,然后当您变得更加自信时,您就可以疯狂了。
还使用逗号分隔每个帧设置,并在为帧设置值时使用句号。有点混乱,但你会习惯的。
本节中最后两个非常重要的参数是 noise_schedule 和 strength_schedule。
与角度或缩放一样,您可以为不同的帧设置不同的值,您可以通过噪声和强度来实现。
噪点意味着您希望在每一帧中添加多少颗粒。它导致更多的扩散多样性。我通常选择 0.02 或 0.03。
强度意味着您希望下一帧与前一帧有何不同。如果将值设置为 1,则表示它将与前一个完全不同。0 表示它将与前一个相同。我通常选择 0.62。
对比度我总是保持在 1。
其余的动画设置
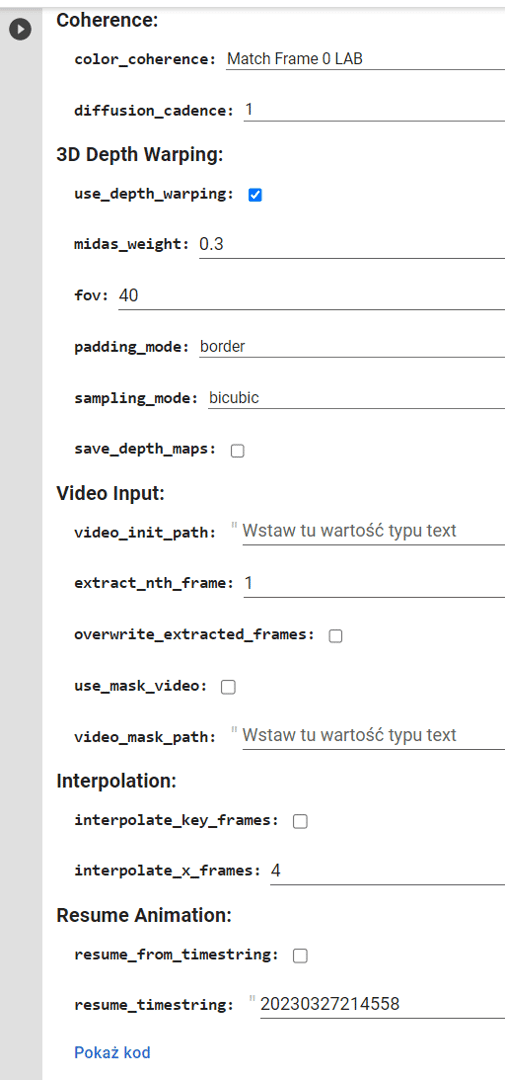
我们可以跳过 3D 深度变形,因为我们现在正在做 2D 动画。
此外,Videoinput 用于视频到视频设置,因此我们不会深入了解这些细节。
Interpolation 是一个有趣的选项——如果你标记这个选项并给值 4,这意味着它将创建每四个图像并融合它们之间的所有帧。它加快了动画过程,可能会给视频带来一点控制,但最终会使视频变得更加模糊。如果你想使用这个选项,我会推荐值:2
本节中最重要的选项是 Resume Animation。例如,如果您的动画由于系统崩溃、缺少互联网或您的积分用完而在中间停止,您可以从停止的地方继续。只需标记此选项并将创建的任何图像文件名称的前 12 个数字作为值。
提示
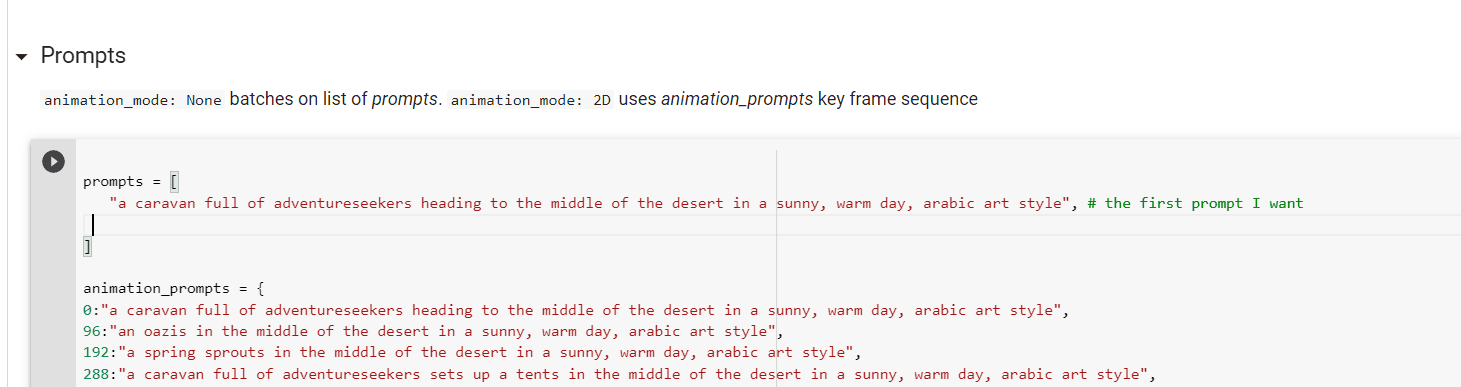
所以我们想在动画中看到的东西。及时的工程或我们与稳定扩散模型(或任何其他 LLM)交流的方式是当今生活中非常重要的一部分。我邀请您尝试其他方式/命令/沟通方式。在屏幕截图中,您可以看到我的一些提示。我总是喜欢详细描述我想看的东西,一些关于灯光或一天中的时间的细节,以及艺术风格或文化推荐。我不喜欢使用某些艺术家的作品名称和名字,但我看到许多伟大的一代人都放弃了名字。
第一个选项是如果你只生成一个图像,而不是整个动画(所以在动画设置中你选择了“无”选项)。
第二个选项是我们感兴趣的选项。您始终需要给出第一个提示。如果你想在第 131 帧有不同的提示,只需输入
131:“和提示”,
就是这样。
但是我建议您先测试提示,然后在最终动画中使用您喜欢的提示。有时惊喜或人工制品真的很有趣,但我建议您使用您事先接受的效果。
让我们创建动画吧!
我们快完成了,只是最后的设置,您已准备好开始使用稳定扩散模型的冒险!
最后设置
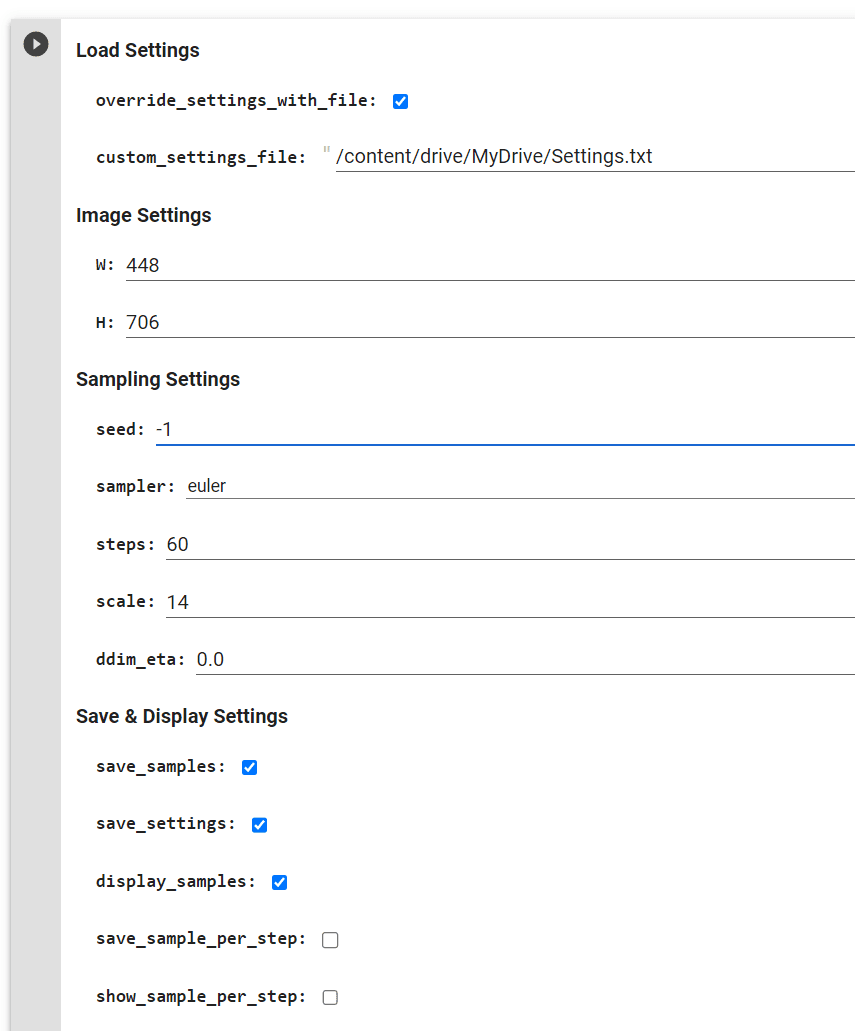
我建议始终标记 override_with_file 选项。这样您将始终保存您的设置,您可以返回它们/重新使用它们或共享它们🙂
图像设置——如果你想要 9:16,我会推荐 448 x 706。对于垂直 706 x 448 和方形 512 x 512。
对于采样设置 – 如果您已经选择了喜欢的种子,请将其放入种子行。如果你想让它随机,那就选择-1。
我建议您使用 50 / 60 步的值。这是一个选项,Defoum 在选择要向您展示的图像之前会对图像进行多少代。
我推荐的比例值在 7 到 12 之间。
点击“生成”之前的最后一次触摸
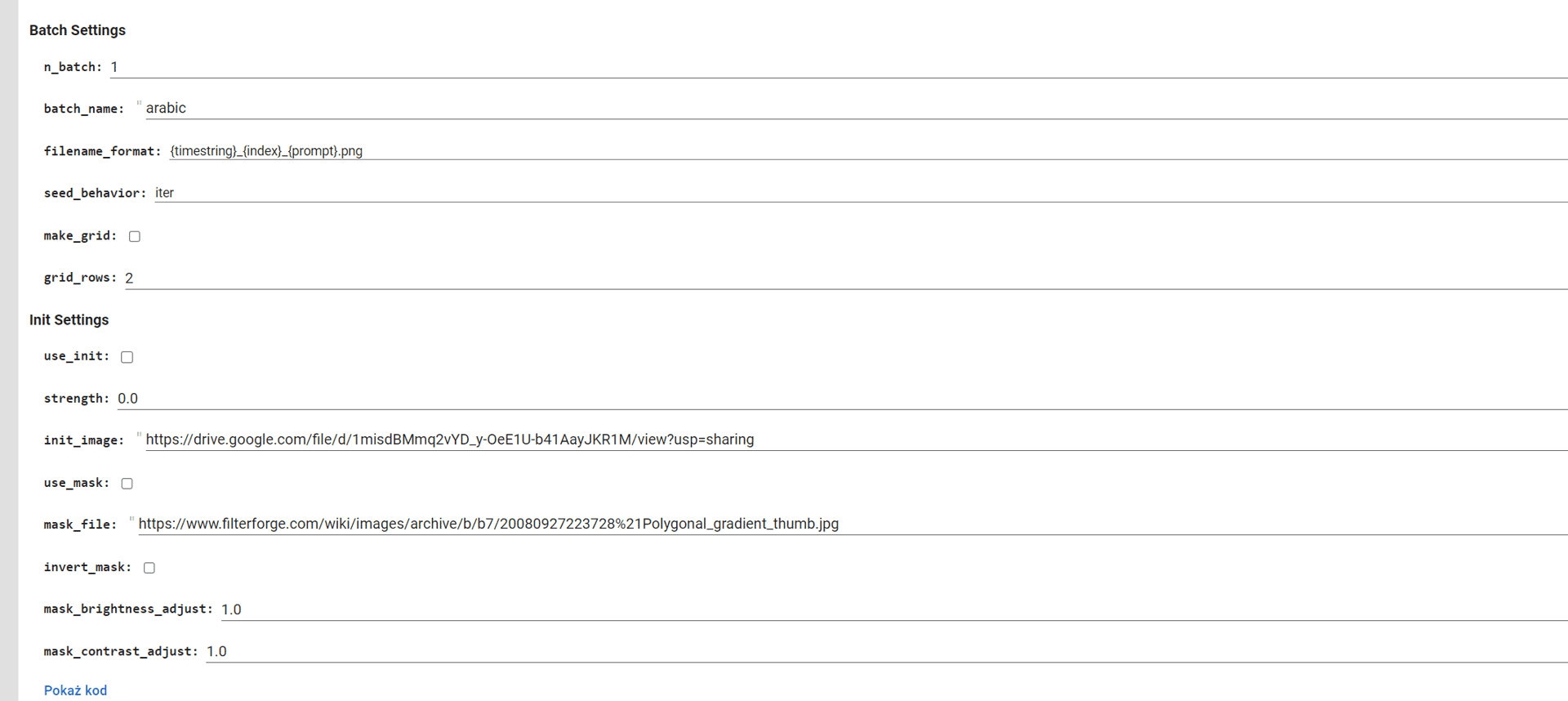
是的,我没有说谎 – 在 batch_name 中,您只需要命名要保存所有图像的文件夹,然后您就可以点击生成。
欣赏您的视频!
但它只生成图像!
图像序列称为视频。因此,生成视频后要做的最后一步是下载图像并将它们放入视频编辑工具并渲染出视频。很简单。
我总是使用一个免费的工具,它给了你很多可能性,它就是 DaVinci Resolve 18。
就是这样。当然,您可以使用“从帧创建视频”部分中的代码,但它并不总是有效,而且您并不总是可以完全控制视频。所以我跳过了这一步。
最后提示
好的,但是我怎么知道我什么时候想改变音乐的动画
这是这一代人的因素。例如,您觉得您想让视频向左移动 10 秒,然后向右移动 10 秒,在那一刻之后您希望它停止转动并动态放大,因为它会非常适合音乐。没问题。请记住,1 秒是 24 帧。
在角度中,只需键入 0:(1)、239:(1)、240(-1)、479:(-1)、480:(0)
在缩放 0:(1), 479:(1), 480(1.03)
简单的。
如果你想让第一个提示运行 10 秒然后另一个提示接管,你必须:
在 strength_schedule 类型 0:(0.62), 239:(0.62), 240:(1), 241:(0.62)
在动画提示中,您只需输入
0:“提示1”,
240:“提示2”
容易,对吧?
但是图像太小且质量低
这就是您应该先下载它们并在外部工具中渲染它们的原因之一。但这不会解决问题,因为它们太小了,需要升级。我用于升级的工具是 chaiNNer,它也是开源的。只需下载它,下载适合您需要的正确模型,然后将放大后的图像按序列放入 DaVinci Resolve 中。
注意:升级需要一些 GPU,所以对于那个你需要一台更强大的 PC,或者让它运行一整夜或几个晚上,如果视频更大 🙂
现在只有你、人工智能和想象力

我希望本教程能帮助您释放您的创造潜力。我从 YouTube 视频、reddit 帖子和 discord 中学习了有关使用 Stable Diffusion 模型和 Deforum 进行创作的一切知识。在这里,您将一切都集中在一个地方,并提供一些提示和技巧来浏览它。
AIHubPro.cn 上的每个人都相信在获取知识和技术方面的平等。我们希望帮助我们的社区成长,为您提供最好的教程,以及使用尖端技术的可能性。我们相信今天正在塑造未来的领导者,我们希望帮助您成为其中的一员。
用您的作品在社交媒体上标记我们。让创造力和人工智能革命获胜!
如果你找不到创造某种东西的工具,为什么不创造它呢?也许在即将到来的 Stable Diffusion 黑客马拉松期间?今天我们正在建设更美好的明天,因此我们鼓励您成为解决方案的一部分!
我们邀请您检查我们社区创建的项目 – ChatGPT 应用程序、Cohere 应用程序或 Stable Diffusion 应用程序。
如果您喜欢开头的视频,请随时在评论中发表您的想法。